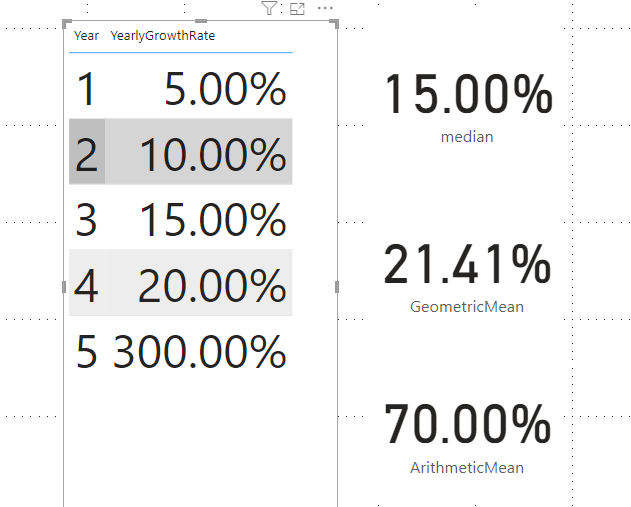
Arithmetic Mean vs. Geometric Mean in Power BI
In this blog post, we will explore the difference between the Arithmetic Mean and the Geometric Mean with some practical examples in Power BI using the built-in DAX function geomean. Arithmetic Mean The arithmetic mean, also known simply as the “mean” or “average,” is the most common measure of central tendency. It is calculated by summing all the values in a data set and then dividing by the number of values. In DAX, you can use the AVERAGE function to…