
Pagination in Fabric Notebook Using Fabric Rest API
In this post, we will see how to perform pagination when calling Fabric Rest API from a notebook.
Note that at the time of writing this post the Fabric REST API is still in preview.
Table of Contents
What is pagination
Pagination is a process used to divide a large dataset into smaller chunks and each smaller chunk contains a pointer to the next smaller chunk until there’s no more chunk.
As Fabric REST API limits the number of records it returns it also supports pagination.
As we will see in this post the API call to retrieve the list of tables can return a maximum of 100 records only per request. With the pointer or URI provided in the response, we can get the next 100 records and send another request to get the next 100 records, and so on until no more records are returned by the API request.
Pagination in Fabric Notebook to retrieve the list of tables
List of Tables Request
To get the list of tables we need to send the following request by passing the Workspace GUID and the Lakehouse GUID as a parameter.

Here is a Sample Request:
GET https://api.fabric.microsoft.com/v1/workspaces/f089354e-8366-4e18-aea3-4cb4a3a50b48/lakehouses/41ce06d1-d81b-4ea0-bc6d-2ce3dd2f8e87/tables
And here is sample response:
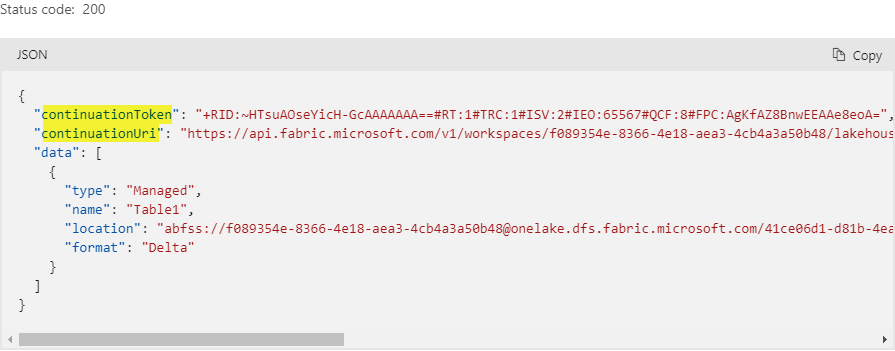
As we can see the response includes a continuationUri or a continuationToken which is what we’re going to use to keep sending requests until we fetch all the tables of our lakehouse.
The notebook
The next step is to create a notebook to request the list of tables and store the results in a delta table. Before executing the code, we need to ensure that semantik-link is installed using %pip install semantik-link or we can set up a custom environment as described in my post Generate Large Sample Data In Fabric.
In the example below, we aim to list all the tables in a lakehouse, which contains 654 tables. This requires making 7 API calls to retrieve the full list. The key point here is that the response contains a “continuationUri” as long as there are more records to fetch. The loop in our notebook will continue as long as the “continuationUri” is not empty and append the dataframe each time we go through the loop.
Here’s a sample code that we can use:
import sempy
import sempy.fabric as fabric
import pandas as pd
import json
from delta.tables import *
workspaceId="Your workspace id"
lakehouseId="Your lakehouse id"
client = fabric.FabricRestClient()
response = client.get(f"/v1/workspaces/{workspaceId}/lakehouses/{lakehouseId}/tables")
ListOfTables = response.json()['data']
df = pd.DataFrame(ListOfTables)
continuationUri="true"
while continuationUri:
continuationUri=response.json()['continuationUri']
if continuationUri:
response = client.get(f"{continuationUri}")
ListOfTables = response.json()['data']
df = pd.concat([df, pd.DataFrame(ListOfTables)], ignore_index=True)
print(len(df.index))
spark.createDataFrame(df).write.format("delta").mode("overwrite").saveAsTable("ListOfTables")
Here is the result of the script:
As we can see our dataframe contains 654 rows which means that we have to make 7 calls to the Fabric Rest API, the first 6 calls will contain a continuationUri and 100 records each, and the last call will contain only 54 records with no continuationUri.
We can then retrieve the list of tables of our Lakehouse from the delta table we’ve just created.

Paginating with Pipeline
Although this post focuses on paginating in notebooks, it is also possible to perform pagination with pipelines, for all the details I’d recommend following my other post on How to perform pagination in Azure Data Factory Using Rest API, the only thing that has changed is that in Fabric the next Token is called “continuationUri” instead of “NextLink” as I explained in my post for the ADF or Synapse REST API.
Conclusion
As we saw in this post, implementing pagination in Fabric with the Fabric REST API is pretty straightforward, whether using notebooks or pipelines. At the moment the Fabric REST API is still in preview and still lacks a lot of features compared to the Power BI, but I’m pretty sure that tons of things are going to be added soon.