
Generate Large Sample Data in Fabric
In this post, we will explore how to generate large sample data in Fabric.
Table of Contents
Why do we need to Generate Large Sample Data in Fabric?
I can think of many many reasons to generate large sample data in Fabric but one of the reasons I see as crucial is for testing performance or to help us decide which tier we should buy for now or in the future.
Today, Fabric offers built-in sample datasets, but they may not suffice for scenarios requiring large data volumes.
Use the existing sample
Use the pipeline copy assistant
Fabric currently offers five sample datasets including the NYC dataset which is the largest among them.
So in this example we will load the NYC Taxi dataset.
To load Fabric’s samples datasets, we can follow the step-by-step guide in Microsoft’s documentation here
In my case it took around 11 minutes to read and write the NYC dataset which is not bad for a P1.

So as we can see, we now have our sample data ready to be used. However, a dataset of 76M rows (roughly 2GB) is probably too small for most performance testing scenarios.
As there’s currently no other larger sample of data provided by Fabric we either have to import our own data or we can use notebooks to generate sample data in Fabric that are much larger than the Nyctlc table.
Generate large sample data in Fabric using notebook and dbldatagen
To generate large sample data in fabric we’re going to use the library dbldatagen
Originally developed for Databricks Notebook, dbldatagen is also compatible with other Spark applications, such as Synapse or Fabric notebooks.
Import dbldatagen to the Fabric Environment
Before creating our Fabric notebook we will first configure our environment so we won’t need to install the libraries each time we start the Fabric notebook.
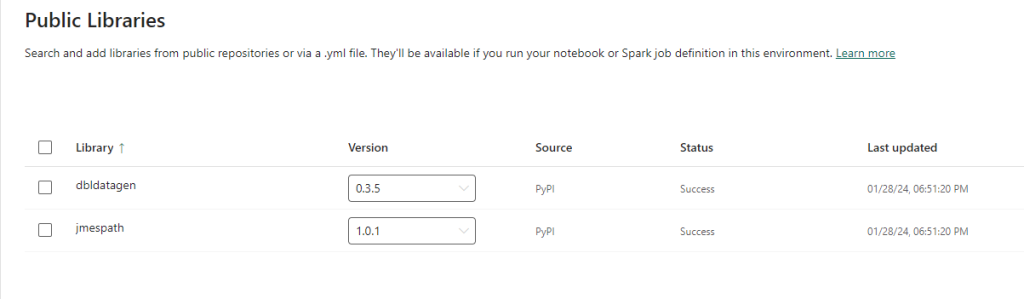
As we can see we have successfully configured our environment and imported the dbldatagen library, we also need to import the package jmespath which is by default already used in the Databricks runtime but not in Fabric. Note that the environment configuration is still in preview so if at this step you encounter any error when importing the libraries you can simply stick to the %pip install your library command in your notebook.
Creating a Billion-Row Delta Table:
Now let’s see how to generate large sample data in Fabric, in the below example we’re creating a delta table of 1 billion rows.
Depending on the config of your spark cluster and Fabric tier it may take a few hours to generate the table.
Here is the spark code:
# Generate Large Sample Data In Fabric
import dbldatagen as dg
from pyspark.sql.types import StructType, StructField, StringType
spark.sql("""Create table if not exists vehicle_data_1B(
name string,
serial_number string,
license_plate string,
email string
) using Delta""")
table_schema = spark.table("vehicle_data_1B").schema
print(table_schema)
dataspec = (dg.DataGenerator(spark, rows=1000000000)
.withSchema(table_schema))
dataspec = (
dataspec.withColumnSpec("name", percentNulls=0.01, template=r"\\w \\w|\\w a. \\w")
.withColumnSpec(
"serial_number", minValue=1000000, maxValue=2000000000, prefix="dr", random=True
)
.withColumnSpec("email", template=r"\\w.\\w@\\w.com")
.withColumnSpec("license_plate", template=r"\\n-\\n")
)
df1 = dataspec.build()
df1.write.format("delta").mode("overwrite").saveAsTable("vehicle_data_1B")
And here are the delta files of our delta table vehicle_data_1B:

We can, of course, generate much larger sample datasets with more rows or more columns. There are more ready-to-use scripts on the GitHub page of dbldatagen that you can find here: dbldatagen examples.
In our simple scenario, we could have tweaked the following parameters:
- Rows: The number of rows you want to have in your table
- Partition: This parameter can be omitted, as I did, as I prefer to let Fabric decide on the number of files to generate. It seems that 2GB size was the optimal size for the Fabric engine for this table.
- Serial Number: Choose the min and max value wisely as you may need to test different scenarios with low or high cardinality columns, like massive delete, massive update, merge, etc.
- percentNulls: Whether or not you want to have nulls if you want to handle such scenarios
Conclusion
This was just an overview of how to generate large sample data in Fabric using the library dbldatagen, for more examples, make sure to check the GitHub page or the official documentation, which will allow you to generate and customize large datasets to better fit your testing scenarios.
4 thoughts on “Generate Large Sample Data in Fabric”
Hi Ben, thank you for sharing. Unfortunately, the code didn’t run well in my environment.
When we try to save it in a delta table, I have the following error.
Any suggestion?
Py4JJavaError Traceback (most recent call last)
Cell In[67], line 30
20 dataspec = (
21 dataspec.withColumnSpec(“name”, percentNulls=0.01, template=r”\\w \\w|\\w a. \\w”)
22 .withColumnSpec(
(…)
26 .withColumnSpec(“license_plate”, template=r”\\n-\\n”)
27 )
28 df1 = dataspec.build()
—> 30 df1.write.format(“delta”).mode(“overwrite”).saveAsTable(“vehicle_data_1B”)
File /opt/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py:1521, in DataFrameWriter.saveAsTable(self, name, format, mode, partitionBy, **options)
1519 if format is not None:
1520 self.format(format)
-> 1521 self._jwrite.saveAsTable(name)
File ~/cluster-env/trident_env/lib/python3.10/site-packages/py4j/java_gateway.py:1322, in JavaMember.__call__(self, *args)
1316 command = proto.CALL_COMMAND_NAME +\
1317 self.command_header +\
1318 args_command +\
1319 proto.END_COMMAND_PART
1321 answer = self.gateway_client.send_command(command)
-> 1322 return_value = get_return_value(
1323 answer, self.gateway_client, self.target_id, self.name)
1325 for temp_arg in temp_args:
1326 if hasattr(temp_arg, “_detach”):
Hi Washington,
Did you install both libraries dbldatagen and jmespath?
Try to run these commands before
%pip install dbldatagen
%pip install jmespath
Ben
Also there should be an icon “diadnostic” on top of the error emssage that may provide more details on the rror that you got
Hi Ben, thank you for your support. It worked now. I was trying to execute this code in MS Fabric, and I don’t know why it did not work the first time.
Thank you, and it is advantageous.