
Load data from Synapse to Fabric
In this short post, we will cover how to load data from Synapse to Fabric or from Azure Data Factory using Sznapse/ADF pipelines.
Note that at the time of writing this post the feature to load data from Synapse to Fabric is still in preview.
Note that loading data from Synapse to Fabric using Synapse notebooks was already feasible, but these notebooks don’t natively support connections to on-premise SQL databases.
Table of Contents
Why loading data from Synapse to Fabric
In the best world, we would fully rely on Fabric and not pay for any other tools, but as Fabric is still in preview and as it takes time to make the switch from one tool to another there may be several reasons to continue using ADF or Synapse alongside with Fabric.
Some reasons could be as follows:
- On-Premise Data Limitations: Fabric currently lacks support for on-premise data connectors (check the roadmap for more details). While Data Flow Gen2 can handle on-prem data, it often underperforms when dealing with substantial data volumes.
- Complex Transformations: You might have complex data transformations set up in Synapse or ADF that aren’t ready to be migrated to Fabric.
- Parallel Environment Testing: Running both environments concurrently can be beneficial for testing and validation purposes.
Depending on your situation, you might find using Fabric’s shortcut sufficient, especially if your data is already on a data lake. This is particularly true if you’ve been using Synapse serverless. However, if you were using the Synapse dedicated pools, physically moving your data from Synapse to Fabric is as of now unavoidable.
Linked Service (Preview)
The initial step to load data from Synapse to Fabric involves setting up the Linked Service to establish a connection to our Fabric Lakehouse. (The Fabric linked service is still in preview at this time).

We’ll need to specify the Workspace Name and the Lakehouse Name. When opting for this method, ensure your account has appropriate access to both the Workspace and Lakehouse.

However, this straightforward option is not the best since it doesn’t support parameters at this stage. Instead, I recommend using the “Enter Manually” option. This approach allows parameterization, enabling you to reuse your Linked Service across multiple workspaces and lakehouses. The same logic applies to the Service Principal, which we will discuss in the subsequent section.
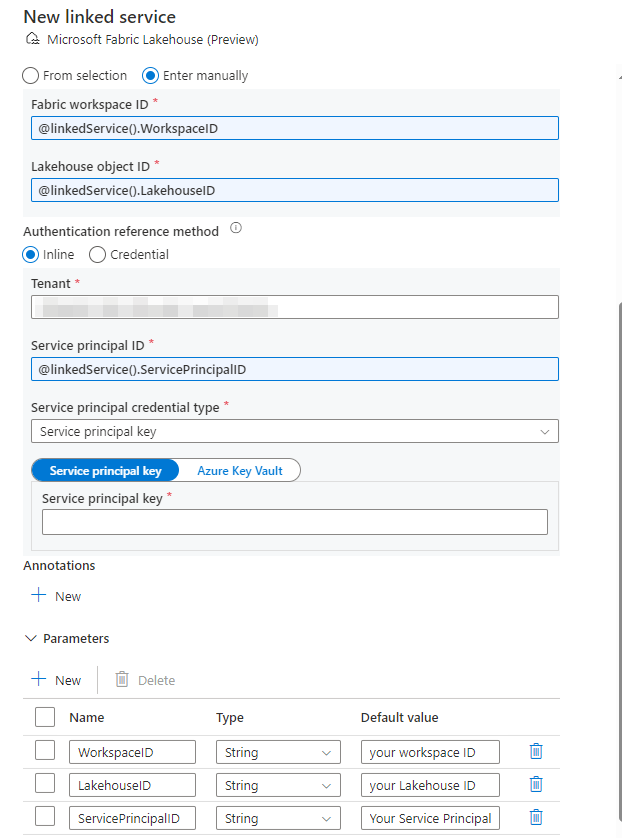
Workspace and Lakehouse ID
If you’re unsure about how to retrieve the Workspace and Lakehouse IDs, here’s a simple guide:
Upon accessing your lakehouse, you will land on a page displaying tables and files. What’s essential here is the URL. The Workspace ID follows “/groups/” within the URL, and the Lakehouse ID follows “/lakehouses/”. Although other methods exist to retrieve this information, using the URL is the most straightforward.

This is a fake URL but it follows the real format of a Lakehouse URL.
Service Principal
For Synapse workspace access, create a service principal within Azure and grant the necessary Lakehouse permissions. Assigning at least the Contributor role within the workspace is essential for enabling the Service Account to perform CRUD operations.
I strongly advocate for securing the Service Principal Key within an Azure Key Vault when configuring the Linked Service.
In order to access your workspace from Synapse we will need to create a service principal in Azure then grant the necessary access inside the Lakehouse. We will need to give at least the Contributor role in the workspace to allow the Service Account to perform CRUD operations.
I strongly advocate for securing the Service Principal Key within an Azure Key Vault when configuring the Linked Service.

Creating a New Dataset
Next, we’ll need to create a new dataset, choosing between ingesting data as Files or as a Table. Opting for Files allows content consumption via Fabric Notebooks but not via the SQL endpoint. However, choosing Table creates a delta-table, accessible directly through the Lakehouse SQL endpoint.
Your specific needs, such as a one-off migration or a structured Bronze layer, will determine whether you store your data as files or tables. Keep in mind that the automatic application of V-order optimization is not applied when loading data from Synapse to Fabric with this approach; to optimize your table, you will need to apply V-order manually using a Fabric Notebook.
The pipeline
Setting the Fabric Linked Service parameters
First, we need to set the parameters for the pipeline which include:
- The target table name
- Workspace ID
- Lakehouse ID

You can skip this part if you don’t want to set dynamic parameters inside your linked service and use only static values.
Copy Data
Source
In the example below, I’m using SQL Server, but we can use any previously configured data source:
To learn more about how to dynamically configure a dataset and use the incremental method to load on-premise data into Synapse, you can refer to my previous post here:: INCREMENTALLY LOAD DATA FROM SQL DATABASE TO AZURE DATA LAKE USING SYNAPSE

Sink
For the Sink, we can use the previously configured Fabric dataset. In my example, I chose to create a new table during dataset setup.

Performance and Optimization
Note that I’ve skipped the settings part as it is beyond the scope of this post but some optimisations can be done there.
Depending on your source type, performance optimization during the setup phase can significantly impact results.
In a test scenario using an 850 million row, 68GB parquet file, it took under six hours to load and convert the single parquet file to 96 delta-files.
Also, cross-region activities (which was my scenario) may slightly degrade throughput, so performance will vary based on your data’s location. Additionally, be mindful of the costs associated with cross-region data egress.

Conclusion
This article aimed to outline how to leverage existing pipelines for direct data ingestion from Synapse to Fabric. While other migration or integration methods may exist, the native connection capability between Synapse to Fabric presents a valuable option for hybrid or migration solutions.