
How to perform pagination in azure data factory using Rest API
REST APIs typically have some mechanism to transmit large volumes of records broken up into pages of results. In this post, I describe how to perform pagination in azure data factory or Synapse pipeline using the Azure REST API.
Table of Contents
What is pagination
Azure REST API limits the number of items it returns per result, so when the results are too large to be returned in one response we need need to make multiple calls to the rest API.
So when the results are too large to be returned on one page, the response includes the “nextLink” which is the “URL” pointing to the next page to call and this continues until we reach the last page.
Here is an example of the “nextlinK” property returned in the body response:
{
"value": [
<returned-items>
],
"nextLink": "https://management.azure.com/{operation}?api-version={version}&%24skiptoken={token}"
}
Now let’s see how to create a simple pipeline to perform pagination in azure data factory.
Pipeline to perform pagination in azure data factory
Get the list of datasets by Factory
For this pipeline, we will retrieve the list of datasets by Factory, this can be useful to retrieve this information when building an enterprise data catalog or data lineage.
At the time of writing this post, the maximum number of datasets that can be returned per request is 50 and there are 67 datasets in my Factory so I need to make two calls to retrieve the whole list.
You can try the Azure rest API and retrieve the URL to call here

And here is the number of datasets in my ADF:

Use Copy activity
The good news is that there’s a built-in function that allows us to perform pagination in azure data factory very easily (This technique applies to ADF and Synapse pipeline for dataflow it is slightly different).
Here are the steps to follow:
- Create a Rest Linked Service if not already done
- Create the datasets Source and Sink
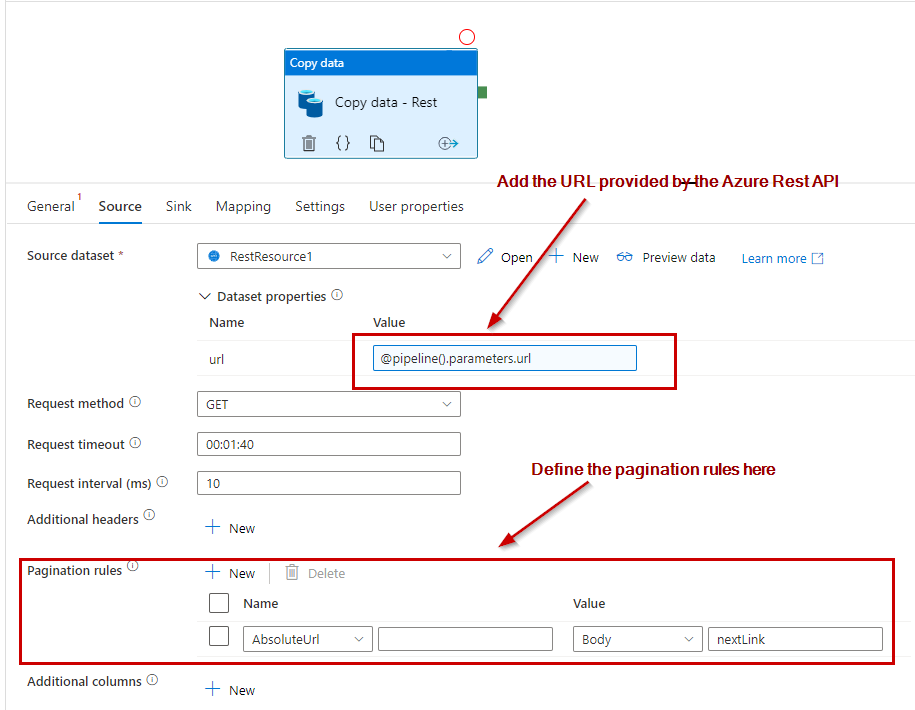
- Source: Rest Dataset and pass the URL provided by “Rest API try it” as a parameter
- Sink: A JSON dataset since the structured response is in JSON format (you can of course parse the JSON response later to fit your needs)
- Create a Copy activity that uses the two created datasets
- Configure the source copy activity
- Configure the sink copy activity
Source copy activity
Here the trick is to define the type of pagination as “body” and the value as “nextLink” we don’t need to set a condition to stop as ADF will automatically stop as soon as the AbsoluteURL will be empty. In some other scenarios, we would probably need to set a condition to stop.
Sink copy activity
Since ADF or Synapse will append the multiple responses into a single file it will break the JSON format and will lead to an invalid JSON file so the trick here is to change the file pattern to “Set of objects” or “Array of Objects”. Power BI can read any of the two patterns thanks to Power Query which easily flattens the JSON structure into a table.

Conclusion
As we saw it is quite straightforward to perform pagination in Azure data factory or the synapse pipeline using Rest API, however, in this post I described only a specific scenario where I needed to retrieve data from the Azure Rest API.
There are many other ways to handle pagination such as offset, range, etc… also handling pagination varies from ADF and Data Flow. Here is the full Microsoft documentation about retrieving data from a REST endpoint by using Azure Data Factory or Synapse.
8 thoughts on “How to perform pagination in azure data factory using Rest API”
Thanks! This is the only solution that worked. I’m surprised this is not properly documented.
Hi Ver,
This is exactly why I posted about it 🙂 And yes I agree it is poorly documented and not up to date.
I did evertything as you described however my pipeline is in status queued all the time
hi Matija,
Are you running the activity in trigger mode or debug mode?
Are you able to run an HTTP request directly from azure and retrieve your metadata? https://learn.microsoft.com/en-us/rest/api/azure/
Thanks for the blog. Do you know how we can avoid creating JSON file if there are no records in the source?
hi Sujit thanks for the comment,
You can use a web activity before the copy activity to check the oputput and then use an if condition before the copy activity.
Another way potentially more efficient if you want to avoid making 2 api call each time could be to ignore empty json files in a similar way.
For each file –> lookup –>if lookup output empty then ignore else process your file.
Thanks for the blog. Do you know if I could use a Parquet file as a destination?
hi Pckris,
Thanks for your comment yes you can have a sink as parquet but you will need to have an intermediate step in between to parse the json, you can sink to json first then read the json with dataflow for exemple and then sink to a parquet file.