Correlation Coefficient in Power BI using DAX
In this post, I will describe what is the Pearson correlation coefficient and how to implement it in Power BI using DAX.
Table of Contents
What is the Correlation Coefficient
The correlation coefficient is a statistical measure of the relationship between two variables; the values range between -1 and 1. A correlation of -1 shows a perfect negative correlation, and a correlation of 1 shows a perfect positive correlation. A correlation of 0.0 shows no linear relationship between the movement of the two variables.
How to interpret the Correlation Coefficient

To go a bit more in detail we can interpret the correlation coefficient as follows:
- -1: Perfect negative correlation
- Between -1 and <=-0.8: Very strong negative correlation
- Between >-0.8 and<=-0.6: Strong negative correlation
- Between >-0.6 and<=-0.4: Moderate negative correlation
- Between >-0.4 and<=-0.2: Weak negative correlation
- Between >-0.2 and<0: Very weak negative correlation
- 0: No correlation
- Between 0 and<0.2: Very weak positive correlation
- Between >=0.2 and <0.4: Weak positive correlation
- Between >=0.4 and <0.6: Moderate positive correlation
- Between >=0.6 and <0.8: Strong positive correlation
- Between >=0.8 and <1: Very strong positive correlation
- 1: Perfect positive correlation
One very important thing to remember is that when two variables are correlated, it does not mean that one causes the other. Correlation does not imply causation
The Formula
Unlike in Excel, there’s no DAX built-in correlation function in Power BI (at the time of writing this post).
In Excel, the built-in function is called Correl, this function requires two arrays as a parameter (X and Y).
The Correl formula used in Excel is as follows:

There are actually several ways of writing the Pearson correlation coefficient formula but to keep consistent with the formula used in Excel I will stick with the above formula which is one of the most common anyway.
Calculate the Correlation Coefficient with DAX
Since we saw the formula above we now need to translate it into DAX.
So let’s break down the formula:
- The Σ (sigma) symbol is used to denote a sum of multiple terms (x1+ x2+x3..) which is an equivalent of sum or sumx
- x̄ (mu x bar), is used to represent the mean of x
- ȳ (mu y bar), is used to represent the mean y
- √ is the square root its dax function is sqrt
Now let’s see the DAX code for the Pearson correlation formula:
Let’s visualise it in Power BI
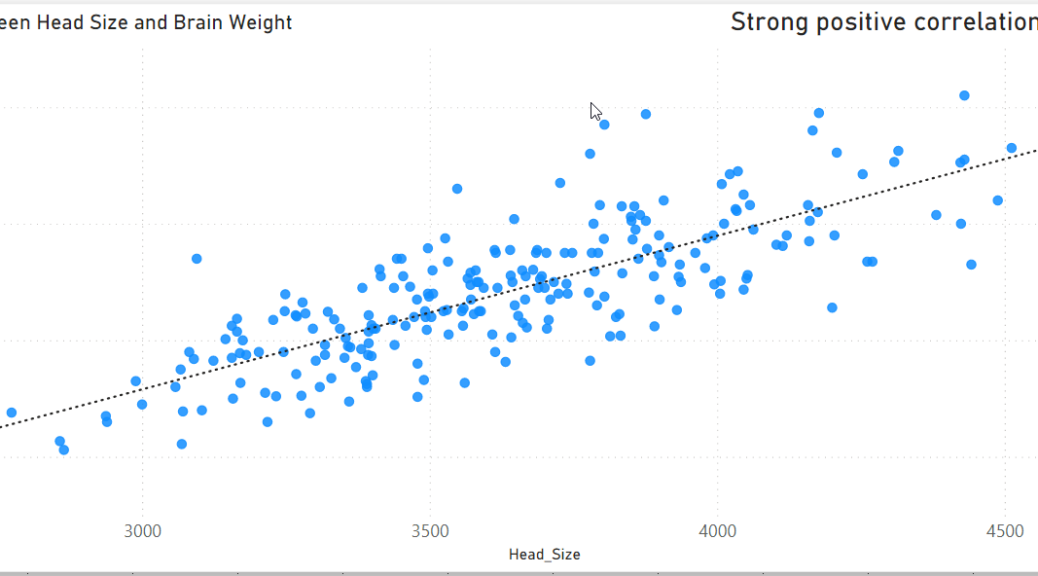
Let’s now build a small report that will show the correlation between the head size (x) and the brain weight (y).
The data are as follows:
- Head_Size (variable x)
- Brain_Wight (variable y)

In Power BI when clicking on the Analytics icon we can easily add a trend line to visualize the relationship between two variables on a scatter plot.

However, to show the correlation coefficient on top of the trend line we still need to create a DAX measure that I have called “coeff corr”.

And as the final touch let’s create another measure “coeff correl type” that will return the interpretation of the correlation so we can display it on top of our visual.
And this is how things look like when we concatenate our “coeff corr” with the “coeff correl type” measure and add them on top of our scatter plot.

The Power BI
Conclusion
This is just another post on the series of implementing statistical functions in DAX you can read some other similar posts in my blog such as AB testing in Power BI or Poisson distribution in Power BI.
Power BI is still lacking some advanced statistical functions compared to Excel but with DAX we can write almost any existing Excel function!
15 thoughts on “Correlation Coefficient in Power BI using DAX”
Ben,
What did you put in the details of your chart?
what if we have very large table dax can’t calculate very large table?
Hi Oded,
For this example, there’s nothing in details I put only two variables in my chart X–> Head size and Y–> Brain Weight and the dataset is very small (a few hundred rows)
However, I ran it on a bigger model with more than 100M rows and it takes around 2.5sec to compute on my PC which is quite old (with 8 CPU), so on a good server, it should be just fine.
Of course, as this measure is a bit complex the more Cores a machine has the quicker it will get computed.
Thanks for this. I adapted this somewhat to add to my own visuals. This also inspired me to add a dynamic calculation of chi-square to report with a a bar graph and frequency table. Pretty cool! You can see what I did following the link below. Will be reading some of your other posts for more ideas.
https://community.powerbi.com/t5/DAX-Commands-and-Tips/Counting-Columns-for-a-Dynamic-Measure/m-p/2341557#M59106
hi, Mike excellent thanks I’ll definitely have a look at your post!
I should soon write another similar post of this one for the chi2.
This is great. Can you make the pbix file available for download?
Hi Peter sure here is the link to download the pbix file: https://github.com/f-benoit/PowerBI/raw/main/CoeffCorrelation/correl.pbix
Ben,
I recently needed to find a correlation, and ended up with almost the same measure as you.
However, i’m currently not using it because i’m not sure of the results.
Maybe you can help !
For both averages, we use a simple “__muX =calculate(AVERAGE(YourTable[x]))”. However, in the numerator VAR, we use a SUMX to calculate “[x]-__muX”
Isn’t the result wrong ? Using a SUMX, the data will be treated row by row.
CALCULATE(AVERAGE(YourTable[x])) would then be applied row by row. With this in mind, it would mean __muX = [x], therefore [x] – __muX = 0.
I understand that this could very well mean that there is no correlation at all, but these calculations also seem a bit weird, so I am wondering.
Does this make any sense to you at all ?
Hi Marius,
If you type “CALCULATE(AVERAGE(YourTable[x]))” inside the SUMX you’re right “it would mean __muX = [x], therefore [x] – __muX = 0” because the avg would be calculate for each row in its row context.
However, in my dax expression, I calculated the average inside a variable so the average is only evaluated in the context of the variable definition not where it is used.
So as you go through each row inside the sumx the result of the variable __muX is never recalculated. Hope that makes sense?
Ben
hello
I have the following exercise, and it is that I need to calculate this statistic for several variables, to be able to make that graphical correlation I use two different tables and thus the correlation X1 (table 1) with X2 (table 2) changes, or the correlation X1 (table 1) with X3 (table 2). What could I do to calculate the covariance if I have this way of relating.
Hi Charle,
I’m not too sure to understand your question, even if it is possible to calculate a covariance for more than 2 variables it would be very hard to interpret since we will not be able to distinguish how X2 and X3 contribute to the covariance result.
However, if you want to calculate the covariance for each combination X1 with X2, X1 with X3 … I would either create one measure for each combination or create a dynamic measure.
How come the sample size or population size (n) doesn’t come into play here? I beginning with statistics and don’t understand why it is missing.
Hi Bill,
The sample size (n) will come into play when we will need to test the significance of the correlation coefficient which is not covered in my post.
Basically, even if the coeff of correlation “r” shows a strong relationship let’s say “0.8” between two variables it does not mean that we can rely on it to make a prediction we have first to test if this result is significant.
So the bigger the sample is the better, here is a link that goes into more detail as you will see the formula to evaluate the significance of “r” uses the size of the sample “n”
https://stats.libretexts.org/Bookshelves/Introductory_Statistics/Book%3A_Introductory_Statistics_(OpenStax)/12%3A_Linear_Regression_and_Correlation/12.05%3A_Testing_the_Significance_of_the_Correlation_Coefficient
Hi,
Used this code to calculate the coeficient. I also used the Linestx() function to get the coeficient of determination and by taking it to the power of 2 I got the coeficient of correlation. When comparing the approachings there’s a slightly difference, which I haven’t figure out.
Do you have any approach using the Linestx()?
teste_ =
VAR _regressiontable =
LINESTX(
DISTINCT(Dim_Calendario[code_calday_key]),
[so_soma_num_de_degustacoes],
[so_soma_num_de_abordagens_dg], TRUE
)
VAR slope =
SELECTCOLUMNS(_regressiontable, [Slope1])
VAR r_sqrd =
SELECTCOLUMNS ( _regressiontable, [CoefficientOfDetermination] )
VAR r = IF(slope < 0, -1, 1) * SQRT(r_sqrd)
RETURN r
—Approach based on the article
x =
//x̄
VAR _Avg_Abordagem =
AVERAGE(Fact_Degustacao_Efetiva[quant_abordagem_dia])
//ȳ
VAR _Avg_Dg =
AVERAGE(Fact_Degustacao_Efetiva[quant_degustacao_dia])
var __numerator =
SUMX(
VALUES(Dim_Calendario[code_calday_key]),
( CALCULATE(MAX(Fact_Degustacao_Efetiva[quant_abordagem_dia])) – _Avg_Abordagem)*(CALCULATE(MAX(Fact_Degustacao_Efetiva[quant_degustacao_dia]))-_Avg_Dg )
)
var __denominator=
SQRT(SUMX(VALUES(Dim_Calendario[code_calday_key]),(CALCULATE(MAX(Fact_Degustacao_Efetiva[quant_abordagem_dia])) – _Avg_Abordagem)^2)*
SUMX(VALUES(Dim_Calendario[code_calday_key]),(CALCULATE(MAX(Fact_Degustacao_Efetiva[quant_degustacao_dia]))-_Avg_Dg )^2))
return
divide(__numerator,__denominator)
Hi Luis,
It should be the other way around you get the coeff of determination by taking the square of the coefficient of correlation but your code seems correct anyway since you’re using the root squared of the coef of dertermination.
Since your code looks good I’d double check that the issue is not a rounding issue I would add like 5 decimals to the coeff correl then get the power of 2 of the coeff.
Another issue could be a duplicate in your column code_calday_key or some null values there.
To double check your result I’d export the data and then import them in R (or python if you prefer) and the function “cor” and “lm” and compare the reuslt against Power BI.
Fort the Linest function you can refer to my article where I use a different approcha than yours, I basically create a calculate table instead of handling everything in DAX but your approach seems definitely correct assuming that you have no duplicate in your iterative column.
https://datakuity.com/2023/03/12/multiple-linear-regression-in-power-bi/