Skewness and Kurtosis in Power BI with DAX
In this post, I will describe what Skewness and Kurtosis are, where to use them and how to write their formula in DAX.
Table of Contents
What is Skewness
Skewness is a measure of symmetry, or more precisely, the lack of symmetry. A distribution, or data set, is symmetric if it looks the same to the left and right of the centre point. For a unimodal (one mode only) distribution, negative skew commonly indicates that the tail is on the left side of the distribution, and positive skew indicates that the tail is on the right (see Figure below for an example).

How to interpret the Skewness
In most of the statistics books, we find that as a general rule of thumb the skewness can be interpreted as follows:
- If the skewness is between -0.5 and 0.5, the data are fairly symmetrical
- If the skewness is between -1 and – 0.5 or between 0.5 and 1, the data are moderately skewed
- If the skewness is less than -1 or greater than 1, the data are highly skewed
Postive Skewness
The distribution of income usually has a positive skew with a mean greater than the median.
In the USA, more people have an income lower than the average income. This shows that there is an unequal distribution of income.

Here is another example:
If Warren Buffet was sitting with 50 Power BI developers the average annual income of the group will be greater than 10 million dollars.
Did you know that Power BI developers were making that much money?
Of course, we’re not… the distribution is highly skewed to the right due to an extremely high income in that case the mean would probably be more than 100 times higher than the median.
Negative Skewness
Age at retirement usually has a negative skew, most people retire in their 60s, very few people work longer, but some people retire in their 50s or even earlier.

Application of Skewness
Skewness can be used in just about anything in real life where we need to characterize the data or distribution.
- Many statistical models require the data to follow a normal distribution but in reality data rarely follows a perfect normal distribution. Therefore the measure of the Skewness becomes essential to know the shape of the distribution.
- Skewness tells us about the direction of outliers. The positive skewness is a sign of the presence of larger extreme values and the negative skewness indicates the presence of lower extreme values.
- Skewness can also tell us where most of the values are concentrated.
Skewness is also widely used in finance to estimate the risk of a predictive model.
Calculate Skewness in Power BI with DAX
At the time of writing this post, there’s no existing DAX function to calculate the skewness, this function exists in Excel since 2013, SKEW or SKEW.P.
The formula used by Excel is the “Pearson’s moment coefficient of skewness” there are other alternatives formulas but this one is the most commonly used.
Calculate in DAX the Skewness of the distribution based on a Sample:
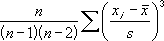
Sample data refers to data partially extracted from the population.
Calculate in DAX the Skewness of the distribution based on a Population:

The population refers to the entire set that you are analysing.
The difference between the two resides in the first coefficient factor “1/N” vs “N/((N-1)*(N-2))” so in practical use the larger the sample will be the smaller the difference will be.
What is Kurtosis
One of the most common pictures that we find online or in common statistics books is the below image which basically tells that a positive kurtosis will have a peaky curve while a negative kurtosis will have a flat curve, in short, it tells that kurtosis measures the peakedness of the curve.

The above explanation has been proven incorrect since the publication “Kurtosis as Peakedness, 1905 – 2014. R.I.P.” of dr. Westfall. So the most correct interpretation of Kurtosis is that it helps to detect existing outliers.
How to interpret Kurtosis
“The logic is simple: Kurtosis is the average of the standardized data raised to the fourth power. Any standardized values that are less than 1 (i.e., data within one standard deviation of the mean, where the “peak” would be), contribute virtually nothing to kurtosis, since raising a number that is less than 1 to the fourth power makes it closer to zero. The only data values (observed or observable) that contribute to kurtosis in any meaningful way are those outside the region of the peak; i.e., the outliers. Therefore, kurtosis measures outliers only; it measures nothing about the “peak“.
Application of Kurtosis
Similar to Skewness, kurtosis is a statistical measure that is used to describe the distribution and to measure whether there are outliers in a data set.
And like Skewness Kurtosis is widely used in financial models, for investors high kurtosis could mean more extreme returns (positive or negative).
Calculate Kurtosis in Power BI with DAX
At the time of writing this post, there’s also no existing DAX function to calculate the Kurtosis, this function exists in Excel, the function is called Kurt.
The formula used by Excel is an adjusted version of Pearson’s kurtosis called the excess kurtosis which is Kurtosis -3.
It is very common to use the Excess Kurtosis measure to provide the comparison to the standard normal distribution.
So in this post, I will calculate in DAX the Excess Kurtosis (Kurtosis – 3).
Calculate in DAX the Excess Kurtosis of the distribution based on a Sample:

Calculate in DAX the Excess Kurtosis of the distribution based on a Population:
Conclusion
In this post, we covered the concept of skewness and kurtosis and why it is important in the statistics or data analysis fields.
At the time of writing this post, there are no existing built-in functions in Power BI to calculate the Skewness or Kurtosis, however, we saw that it is pretty easy to translate a mathematic formula to a DAX formula.
In one of my previous posts “AB Testing with Power BI” I’ve shown that Power BI has some great built-in functions to calculate values related to statistical distributions and probability but even if Power BI is missing some functions compared to Excel, it turns out that most of them can be easily written in DAX!
4 thoughts on “Skewness and Kurtosis in Power BI with DAX”
its really great website and great stuff is here
i really like it if u have ur youtube channel then let me know i wanna to subrcribe it
it would be great if u can share file of this topic
Hi Suleman,
I don’t have a youtube channel maybe one day 🙂
I’ll make sure to upload the PBIX file and link it under your comment.
Kurtosis does not measure peakedness or flatness at all. High kurtosis distributions can be either peaked or low and flat-topped, and low kurtosis distributions can be either flat-topped or peaked (even infinitely so). See the current Wikipedia page for examples with graphs.
Hi Peter,
Thanks for the comment and yey absolutely agree and this is what I said in my post just under the graphic–>”The above explanation has been proven incorrect since the publication “Kurtosis as Peakedness, 1905 – 2014. R.I.P.” of dr. Westfall. So the most correct interpretation of Kurtosis is that it helps to detect existing outliers.” https://pmc.ncbi.nlm.nih.gov/articles/PMC4321753/