
Clustering in Power BI using R
Since 2016 there’s a built-in feature in Power BI that allows us to automatically find clusters within our data.
This is a great feature, however, its main drawback is that whenever we add new data into Power BI the clusters need to be manually recalculated for the new data.
In this post, I will show how we can implement clustering in Power BI using R and automatically recalculate the clusters whenever we hit the refresh button.
Table of Contents
What is Clustering
Clustering is the task of dividing the data sets into a certain number of clusters in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups (clusters). It is the main task of exploratory data analysis, and a common technique for statistical data analysis, used in many fields, including pattern recognition, customer segmentation, image analysis, bioinformatics, data compression, computer graphics and machine learning.
There are several types of clustering methods and one of the most simple and widely used algorithms is called K-means clustering.
It partitions the data points into k clusters based upon the distance metric used for the clustering. The value of “k” is to be defined by the user. The distance is calculated between the data points and the centroids of the clusters.
K-means was the algorithm used in SSAS data mining, however, I can’t seem to find which algorithm is used in the built-in clustering feature of Power BI but I believe that this is also K-means.
Built-in Clustering in Power BI
To find more about how works the clustering feature in Power BI you can refer to this Microsoft Power BI article: CLustering feature in Power BI
So as we can see from the description in the link above, we can ask Power BI to automatically find clusters within our data either by using a table visual or a scatter chart visual or we can choose the number of clusters we want.

It takes some time for Power BI to calculate the clusters depending on the dataset size and the number of measures that we want the algorithm to analyse to find clusters.
Once the clusters are identified we can save them and rename them, however, our clusters will not be re-evaluated on refresh so whenever we add new data we will need to manually rerun the clustering.
This is the main reason why I’m writing this post, I needed a simple way to automatically refresh the clusters whenever new data were added to the model.
The data
For this post, I’m using a small and simple dataset that contains the starting and mid-career median salary for each undergraduate Major in the US. Then using the clustering method we will group each Major into different clusters.

By plotting the data into a scatter chart we can see some sort of patterns such as:
- Starting and Mid-career: low salary
- Starting and Mid-career: average salary
- Starting and Mid-career low salary: high salary
- There’s also some outliers

Run automatically find clusters in Power BI
Now if we run the built-in automatic find clusters (auto) in Power BI we get the following output.
PowerBI has automatically identified 3 main clusters and the Cluster4 with a unique point.
I’m not going to get into the technical details but K-means is not robust to outliers as we can see below centroids can be dragged by outliers and end up being clusters made of a single value.

Now let’s add more data to the Power BI model and hit the refresh button.
I’ve added 10 new Majors and refreshed my model now the problem is that my clusters are not re-evaluated and thus the new majors are displayed as Blank and not grouped with the existing clusters.

So to overcome this limitation in a simple and quick way we can take advantage of the R or Python integration within Power BI and then implement our K-means algorithm and make sure it re-evaluates all the data whenever we refresh the model.
Implement Clustering in Power BI using R
Run the R script in Power BI
Here the most difficult part is not to write some R or Python code as K-means can be written in just a couple of lines of code.
The complexity is to make K-means user-friendly which means that we don’t want to hard code anything so that we can dynamically change the parameters of K-means like it is done in Power BI (number of clusters, measures to use and column to analyse).
As we can see in the image below in Power BI we can easily pass the number of clusters or which measures to use for the cluster analysis. To implement clustering in Power BI using R and to reproduce something similar to the built-in feature, we need to create and use some parameters.

What are the parameters that we need?
So what do we need to do to make Clustering in Power BI using R as user-friendly as possible?
- We need the ability to choose the number of clusters
- We need the ability to let K-means automatically decide the best number of clusters to use
- We need that ability to choose which measures to use for the clustering analysis
So technically we need one parameter for the number of clusters and one parameter for each measure we want to use (I limit the number of measures to use to five in this example).
Retrieve the list of columns/measures
First, we need to retrieve the list of columns and measures and make a list out of it.
So using power query I used the following steps (there may be a better way of achieving it)
- Reference the main dataset
- Demote header
- Keep only the first row
- Transpose the columns into rows
- Add “empty” (for unused measures this can be improved)
- Transform the table to a list
let
Source = #"degrees-that-pay-back",
#"Demoted Headers" = Table.DemoteHeaders(Source),
#"Kept First Rows" = Table.FirstN(#"Demoted Headers",1),
#"Transposed Table" = Table.Transpose(#"Kept First Rows"),
#"CustomRow"= Table.InsertRows(#"Transposed Table" ,2, { [Column1 = "Empty"] }),
#"Sorted Rows" = Table.Sort(#"CustomRow",{{"Column1", Order.Ascending}}),
Columns1 = #"Sorted Rows"[Column1]
in
Columns1
I also created a parameter “num_clusters” which allows us to pass the chosen number of clusters to the R script.

To automatically let the R script find the best number of clusters we need to assign the number of clusters value to 0.

To pass the selected parameter to the R script you can refer to my previous post POWER BI PASS PARAMETER VALUE TO PYTHON SCRIPT, the way Python or R retrieve the parameter value is exactly the same.
The R script
Clustering in Power BI using R script:
# 'dataset' holds the input data for this script
#Load relevant packages
library(cluster)
#library(factoextra)
library(NbClust)
columns <- c('&Column1&','&Column2&','&Column3&','&Column4&','&Column5&')
k_means_data <- dataset[, (colnames(dataset) %in% columns)]
# Set k equal to the optimal number of clustersr
num_clusters <- "&Text.From(num_clusters)&"
dataset["nbcluster"]=num_clusters
if (num_clusters==0) {
clusters <- NbClust(k_means_data, distance = "euclidean", min.nc = 3,
max.nc = 10, method = "kmeans")
clusters=clusters$Best.partition
dataset=cbind(dataset,clusters$Best.partition)
} else {
# Run the k-means algorithm with the specified number of clusters
k_means <- kmeans(k_means_data , as.numeric(num_clusters) , iter.max = 15, nstart = 25)
# Add back the cluster labels to df for use in our upcoming visualizations
dataset$clusters <- k_means[[1]]
}
And the final Power Query script is as follows:
let
Source = #"degrees-that-pay-back",
#"Run R script" = R.Execute(
"# 'dataset' holds the input data for this script#(lf)#Load relevant packages#(lf)library(cluster)#(lf)#library(factoextra)#(lf)library(NbClust)#(lf)columns <- c('"
& Column1
& "','"
& Column2
& "','"
& Column3
& "','"
& Column4
& "','"
& Column5
& "')#(lf)k_means_data <- dataset[, (colnames(dataset) %in% columns)]#(lf)# Set k equal to the optimal number of clustersr#(lf)num_clusters <- "
& Text.From(num_clusters)
& "#(lf)k_means_data<-scale(k_means_data)#(lf)if (num_clusters==0) {#(lf) clusters <- NbClust(k_means_data, distance = ""euclidean"", min.nc = 3,#(lf) method = ""kmeans"") #(lf) clusters=clusters$Best.partition#(lf) dataset=cbind(dataset,clusters)#(lf)} else {#(lf) # Run the k-means algorithm with the specified number of clusters#(lf) k_means <- kmeans(k_means_data , as.numeric(num_clusters) , iter.max = 100)#(lf) # Add back the cluster labels to df for use in our upcoming visualizations#(lf) dataset$clusters <- k_means[[1]]#(lf)}#(lf)output=dataset",
[dataset = Source]
),
output = #"Run R script"{[Name = "output"]}[Value]
in
output
Run and Refresh our K-means with new data
This is the output of when I refresh the custom clustering in Power BI using R, as we can see the outlier has been grouped with the cluster3. This is because the initial centroid selection is random and K-means is sensitive to the initialization condition, K-means may converge to only a suboptimal solution when the initial centroids are chosen badly.

Now let’s add new data to our Power BI model and refresh it. As we can see the clusters are automatically re-evaluated, thus, the new input data are automatically grouped with their clusters.

Let’s now change the number of clusters from “Automatic” to 5 clusters:
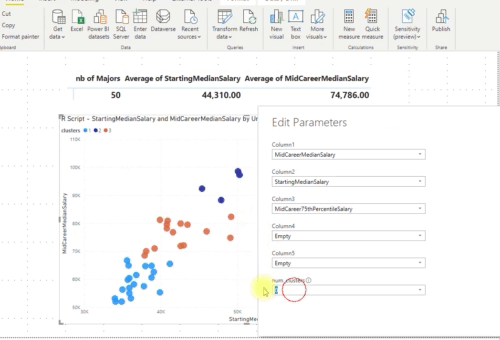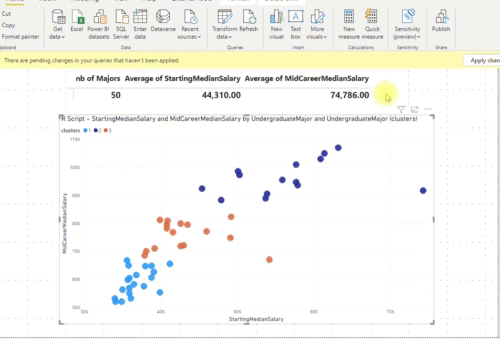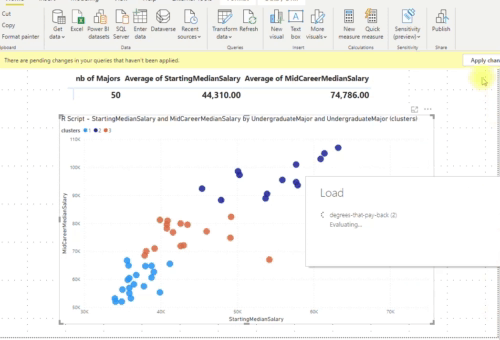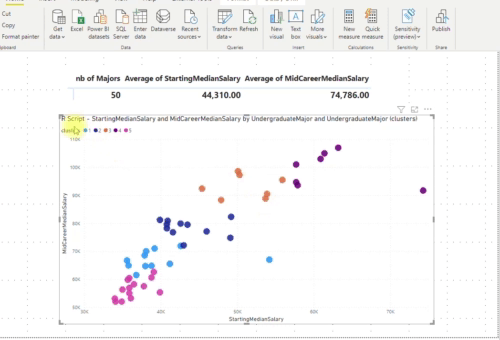
From a user point of view or report designer changing the number of clusters or adding more measures to use is very easy and straightforward. Combining parameters and embedding custom R or Python scripts inside Power Query opens up a lot of possibilities for Power BI!
Conclusion
In this post, I’ve described how to Implement Clustering in Power BI using R but we can use the same technique for any other ML algorithms or transformations.
As long as you have someone who can code in R or Python in your team you can do nearly everything that you can do with R or Python.
However, I would definitely not use this approach on a big ML project or large dataset.
Maintaining an R-script within power query can quickly become a pain, so I would only use this approach for a small project where we don’t have the budget and time to develop a real machine learning pipeline and where we don’t need to modify the code very often.
Other alternatives would be to develop a real ML pipeline and insert the output somewhere where Power BI can directly consume the data. Another solution could be to create and train an Azure ML model and invoke it directly from Power BI.
One thought on “Clustering in Power BI using R”