
AB Testing with Power BI
In this post, I am going to share a step by step guide to implement AB Testing with Power BI.
A/B testing, or split testing, is a digital marketing technique that involves comparing two versions of a web page or application to see which performs better. These two versions, A and B are randomly shown to different visitors at the same time. Then a statistical analysis of the results determines which version performs better according to certain predefined indicators such as conversion rate.
Table of Contents
Goals of this Post
- What is AB testing and when to use it
- Why using Power Bi instead of R/Python
- Implement AB testing with Power BI
- Use some of the advanced DAX Statistical functions
What is A/B testing?
A/B testing is a basic approach to compare two versions of something to figure out which performs better. Even though A/B testing can be used for any experiments it is often used in the digital marketing world (websites, apps, email campaigns…)
So to keep it short and simple A/B tests is the application of statistical hypothesis testing which consist of a randomized experiment with two variants, A and B.
Typically in A/B testing, the variant that gives higher conversions is the winning one, and that variant can help optimize a website for better results. The metrics for conversion are unique to each website.
For eCommerce, it may be the sale of the products, while for B2B, it may be the generation of qualified leads.
For example, an online retail company wants to test the “Hypothesis” that if making the “Add to Cart” button brighter will lead to an increase in the number of people adding items to their shopping carts.

By having the two websites active at once and randomly directing users to one or the other, the online retail company can monitor the impact of making the “Add to Cart” button brighter and then draw conclusions accordingly.
AB Testing with Power BI
Why using Power Bi instead of R/Python?
The main reason I decided to write this post is that I couldn’t find any post on how to implement AB testing with Power Bi with DAX so I thought it would be interesting to try out the advanced statistical functions of DAX.
Obviously, Power Bi is not R, Python or SPSS but I file like the built-in DAX Statistical Functions are just amazing and often underlooked.
So through this post, I want to share the hidden or little known great capabilities of the Power BI statistical functions.
There are also good reasons why we could implement AB Testing with Power BI:
- No python or R knowledge within your company
- Security Policy: Your organisation does not allow r/python script to be deployed in the PowerBi portal
- Integration and deployment more complex
- One tool (no need to invest in a statistical tool)
- One language (easier to maintain)
- Fully interactive visuals (custom visuals using R or Python are not)
- Reusability
- It’s fun 🙂
Create AB testing with Power BI
The data
Before jumping into the advanced Dax Statistical functions let’s see what are the data for which we want to run an A/B testing test.
- One month of data
- Data are split into two groups (Control and Var)
- Over one month there were 6,178 visits and 155 leads disregarding the group assignments
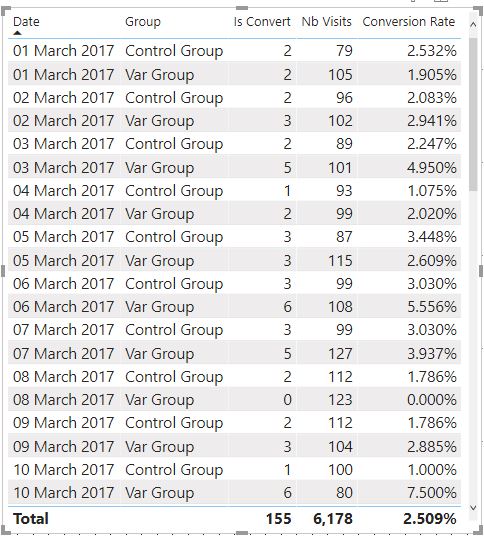
Now let’s visualise the data summarized by groups.

| Ctrl Group | Var Group | |
| Size | 3,036 | 3,142 |
| Conversion | 65 | 90 |
| Conversion Rate | 2.141% | 2.864% |
The variation group seems to perform better as its conversion rate of 2.86% is higher than the conversion rate of the control group.
But how can we be confident that this improvement is the result of the changes we made and not a result of random chance?
Let’s now jump into the statistic functions and answer this question.
Advanced DAX Statistical functions
Conversion Rate
The conversion rate or success rate is the percentage of users who take the desired action. For example, in online retail, the conversion rate is the percentage of website visitors who buy something on the site.
[conversion%]
[Ctrl Group Conversion %]
[Var Group Conversion %]
Confidence Intervals
A Confidence Interval or CI is a range of values we are fairly sure our true value lies in.
In another word, the CI can answer the question of whether the result of our experimentation is the result of the changes we made or the result of random chance.
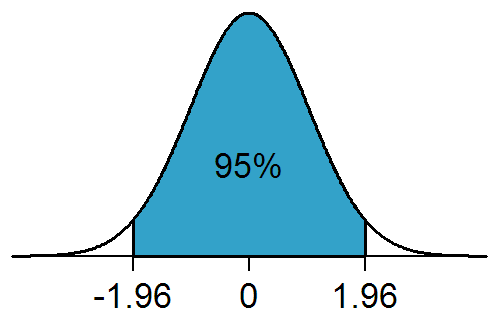
The confidence level should be chosen before examining the data, a 95% confidence level is usually used. However, confidence levels of 90% and 99% are also often used in analysis.
As you will see below I’ve created a z-value table that allows me to choose a CI between 90% and 99%.
Standard Error
The Standard Error is needed to compute the Confidence Interval but what is Standard Error or SE?
If we were to repeat the same AB tests multiple times, we will notice that the conversion rate will vary.
So we use the “Standard Error” to calculate the range of possible conversion values for a specific variation.
For a given conversion rate (CR) and a number of trials (n), the standard error is calculated as:
![SE = \sqrt[]{\frac{CR * (1-CR) }{n}}](https://s0.wp.com/latex.php?latex=SE+%3D+%5Csqrt%5B%5D%7B%5Cfrac%7BCR+%2A+%281-CR%29+%7D%7Bn%7D%7D&bg=ffffff&fg=000&s=2&c=20201002)
[std_Error]
In order to simplify the next formulas, I compute the SE for each group (Control and Variation)
[Ctrl SE]
[Var SE]
Conversion Rate Upper and Lower Limit
Since I’ve calculated the Standard Error I can now compute the upper limit and lower limit of the conversion rate based on a specific confidence interval defined by the Z-value.
Conversion Rate Lower Limit
Conversion Rate Upper Limit
Z-Value
Below is a table that contains the different values for Z and Alpha.
Youn can find more information about Z-table here.
To keep it short the Z-table represents the values of the cumulative distribution function of the normal distribution. It is used to find the probability that a statistic is observed below, above, or between values on the Z distribution or standard normal distribution.
| Confidence Interval | Z value | Hypothesis | Alpha |
| 80% | 0.8416 | One-Sided | 0.2 |
| 85% | 1.0364 | One-Sided | 0.15 |
| 90% | 1.2816 | One-Sided | 0.1 |
| 95% | 1.6449 | One-Sided | 0.05 |
| 99% | 2.3263 | One-Sided | 0.01 |
| 80% | 1.282 | Two-Sided | 0.1 |
| 85% | 1.440 | Two-Sided | 0.075 |
| 90% | 1.645 | Two-Sided | 0.05 |
| 95% | 1.960 | Two-Sided | 0.025 |
| 99% | 2.576 | Two-Sided | 0.005 |
For example, in statistics, 1.96 is the approximate value of the 97.5 percentile of the Z distribution which means that 95% of the area under a normal curve lies within roughly 1.96 standard deviations of the mean.
Z-Score
A Z-score is a number that describes a value’s relationship to the mean of a group of values.
Z-score is measured in terms of standard deviations away from the mean.
Z-scores may be positive or negative, with a positive value indicating the score is above the mean and a negative score indicating it is below the mean.
The Z-score formula is as follows:

Uplift
Uplift is simply the relative increase in conversion rate between Group A and Group B. It is possible to have negative uplift if our Control group is more effective than the new Var group. Here is the formula:

- Var Group Conversion % = 2.864%
- Ctrl Group Conversion % = 2.141%
- Uplift = 2.864/2.141-1=33.79%
- (The Var group is 33.79% more effective than the Ctrl group)
Now using the Standard Error measure and Z-value we can also compute the minum and maximum expected Uplift within a specific level of confidence.
Maximum Uplift
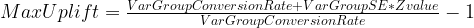
Minimum Uplift

P-Value
A p-value is used in hypothesis testing to either support or reject the null hypothesis. The p-value is the evidence against a null hypothesis. The smaller the p-value, the stronger the evidence that you should reject the null hypothesis.
In our scenario depending on the type of the test one or two-tailed the Null hypothesis states:
The two-tailed test takes as a null hypothesis that both groups have equal conversion rates.
The one-tailed test takes as a null hypothesis that the variation group is not better than the control group, but can actually be worse.
Here is the formula to calculate the p-value based on the Confidence Interval selected (Z-score):
Power
Power or “1 -Beta“, is used to explain the strength of our test to detect an actual difference in the Variation group.
Conversely, Beta is the probability that our test does not reject the null hypothesis when it should actually reject it. The higher the power, the lower the probability of a Type II error.
Experiments are usually set at a power level of 80%, or 20% Beta.
Here is the formula to calculate the Power:
AB Testing in Power BI
Now that we have defined all the measures let’s plug everything together.
Here is the final AB Testing with Power Bi report.
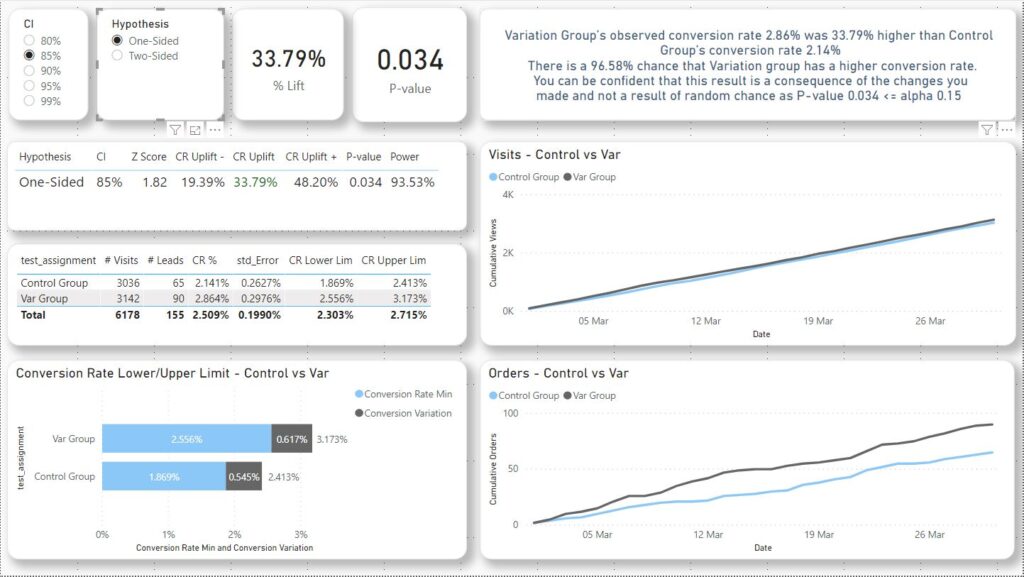
Line Chart – The number of visits Control vs Var

Line Chart – The number of orders Control vs Var

Confidence Interval and Test type Slicers & Uplift and P-value KPIs

To get the CI and Hypothesis data populated I just entered the data manually (see Z-score section)
Table – Z-score, Uplift Lower/Upper, P-value and Power

Here I use CI=95% for a Two-Tailed test so to reject the null hypothesis the p-value must be under 0.025. (1-0.95)/2.
As 0.034 is greater than 0.025 we fail to reject the null hypothesis thus we assume that the increase in 33% of the uplift is due to the chance.
Note: Instead of dividing alpha by 2 we can also multiply by 2 the P-values as the P-value for a two-tailed test is always two times the P-value obtained for the one-tailed tests.
Table – Conversion Rate with Upper and Lower limit for the two groups

Bar Chart – Conversion Rate with Upper/Lower limit for the two groups

Text – Final Result of the Ab testing experiment.

Conclusion
This post is a shallow introduction to AB testing with power BI. It is, of course, impossible to cover all the aspects of AB testing in just a post as there are entire books written on this subject with more advanced concepts which are beyond my knowledge.
However, I really wanted to show that we can easily implement AB testing using Power BI and create the exact same metrics that most of the AB testing tools on the market would provide.
The only requirement would be to plug Power BI onto the data generated by your websites (visits, conversion) and that’s it!
As said above, I could’ve integrated an R or python script in Power BI to get this done but it wouldn’t have added any real value to Power BI.
By using DAX only it really shows that Power BI has great statistical analysis capabilities that I feel are little known.
As I love statistics as much as I love Power BI I hope to write more posts about “Statistical concepts using Dax only “.
Final Note
If you’d like to implement AB testing with PowerBI and test your result I’d recommend using the following AB Testing Calculator simulator:
https://abtestguide.com/calc/
Here is the full PBI report:
Let me know in the comments if you have any questions.
59 thoughts on “AB Testing with Power BI”
Hi Ben,
Nice article, I’m wondering can you give the Excel or CSV data you showed in your example so I can practice on that?
Thanks,
Oded Dror
Hi Oded,
Thanks for your comment.
Here is the dataset:
https://raw.githubusercontent.com/f-benoit/PowerBI_Dataset/main/output%20dax%20ab%20testing.csv
Also note that I only used a subset of the dataset in my post I filtered the dataset on TestName=”Test2″
Let me know if you have any questions/suggestions.
Ben
Hi, plz you tell me where I can get the data set? Thanks,
Hi sure here is the link to the dataset :
https://raw.githubusercontent.com/f-benoit/PowerBI_Dataset/main/output%20dax%20ab%20testing.csv
Hi! Ben
Thanks for very important blog, It has enhanced my prospective on working in Power BI.
My Query :
You have calculated SE (Standard Error ) and in calculation you mention Measure by name of [nb views], please can you define that.
Thanks!
Aditya Kalra
aditya.iq@gmail.com
Hi Aditya,
Thanks for your comment!
The measure nb views is defined as follows “countrows(ConversionRateABTesting)”.
In my dataset one row = one visit, it would have made more sense to call this measure “nb visits” instead of “nb views” actually…
Please check Calculation:
conversion% = Divide(nb visits,nb leads)
Right Answer is :
conversion%= Divide(nb leads,nb visits)
oops yes you’re absolutely right! And thank you for pointing this out I’ll have this fixed now.
In my report, I use the measure “AVERAGE(ConversionRateABTesting[IsConvert])” so this is why it is still showing the right result, otherwise my conversion% would have been completely wrong…
Hi Ben, Is it possible to get the PowerBI template or project file you’ve created for this? Thanks in advance
Hi Hannah,
Here is the link to get the source file used in my post:
https://raw.githubusercontent.com/f-benoit/PowerBI_Dataset/main/output%20dax%20ab%20testing.csv
I will add the PBIX file this weekend as well
Hi Ben,
Great article. Where can I find your PBIX file, have you added it?
Thanks!
Hi Perry,
Thanks for your comment. Here is the link to download the pbix file: https://github.com/f-benoit/PowerBI/raw/main/AB%20Testing/AB%20Testing.pbix
Hi Ben,
Very interesting post (thank you!) and something we would like to emulate. Would be super helpful to have the PBIX file as well to make sure we’re following along correctly. I didn’t see it posted yet.
Thanks!
Hi Kevin,
Yes sure you can download the pbix file here: https://github.com/f-benoit/PowerBI/raw/main/AB%20Testing/AB%20Testing.pbix
Ben
Thanks Ben – really appreciate it!
Hi Ben,
Thanks for the amazing demonstration.
I just have a question about the final result in the text box.
How do you calculate that 96.58% chance that the Variation group has a higher conversion rate? Can you please tell me this?
Jesse
Thank you very much!
Hi Jesse,
Thanks for your comment, I got 96.58 by substrating the p-value from 1. The formula is as follow:
if([Var Group Conversion %]>[Ctrl Group COnversion %] ,
” There is a ” & FORMAT( 1-[P-value], “Percent”) & ” chance that Variation group has a higher conversion rate.” & UNICHAR(10)
,” There is a ” & FORMAT( 1-[P-value], “Percent”) & ” chance that Variation group has a lower conversion rate.” & UNICHAR(10)
)
Hi Ben.
Thanks for sharing. How would I implement such a dashboard for a continous target metric, such as fx revenue?
Thanks
Hi Norman,
It’s a bit difficult to answer this question without knowing how you generate your revenue and what exactly is the hypothesis you want to test.
Based on your questions I can clearly see that you’re not using a clicks/revenue model like I used in my blog.
Now I assume that you’re making X number of transaction each day and that each transaction is either generating a profit or a loss.
What you may do then is to compare two algorithms A and B, invest in the same portfolio and then evaluate the average revenue per transaction or the successful trades (profit/loss) of each algorithm.
For example:
Revenue per algorithm:
Control Algorithm 500 transactions generate revenue of 10,000
Var Algorithm 700 transactions generate revenue of 12,000
Then Revenue per transaction:
Control Algorithm revenue per transaction: 10,000/500=20
Var Algorithm revenue per transaction:12,000/700=17.14
So the “number of visits” is your “number of transactions” and the “conversion rate” is your “revenue per transaction”.
Note that I know very little about FX and that A/B testing is essentially a user experience research methodology so there likely better statistical tests to perform in your scenario… Hope my answer still helps.
Very interesting and important information about Power Bi
Thanks Arpita!
I couldn’t let to comment one of the best materials I’ve ever seen, with statistical analysis and DAX. CONGRATULATIONS !!!
Hi Wellington thanks for your comment!
I concur with Wellington’s comments too Ben, great to see you pushing and blurring the boundaries between usable statistical analysis and scenario modelling in PBI, excellent work….As you indicated the extension would be to have the data piped live and comared predicted performance improvement range with actuals.
Hi Jason,
Thanks for your interesting comment!
So as you said the next step could be to compare the actual performance vs predicted performance.
(First, we assume that at the end of the test the Variation group is a clear winner and we decide to full-scale the change we made.)
To do so we will also need to have good historical data with a clear seasonality pattern in order to first have an accurate prediction of our performance future performance without the change made.
If we are able to accurately predict the expected performance we can then take this prediction and increase it by the % expected uplift and then compare it with the actual performance.
Ben
Hi Ben,
It’s great to see deeper statistical methods being used in such a rigid piece of software like Power BI. Thanks for sharing!
Could you post your sources for where found the formulas and the reasoning behind why you chose the test that you did? I’m curious why you chose to use the z-score in this scenario. Cheers!
Hi Mert,
Sorry for the late reply just realised I still had a pending comment.
If you download the PBI you should find a tab where I put all the resources I used to validate the formulas and results of the output given by the dax code.
Originally it was a small python project which I translated into DAX.
In this scenario, I used the z-value and Z-score to calculate the p-value and the upper and lower limit for a specific confidence interval.
Hi Ben
Nice article , can we apply the same concept for intriducing a new product e.g. (cafee or new type of sandwich) based on transactional data from point of sale (POS) system?
Hi Mohamad,
If you have past data you may compare the sales without the new product versus the sales with the new product.
If you don’t have history but you multiple cafes or fast food you may introduce your new sandwich in one store (var group) and not in the other (control group), to do so you will first need to make sure that there’s a clear correlation between your two stores in term of sales and then use the correlation as a metric for your AB testing.
Hi Ben
Nice article , can we apply the same concept for intriducing a new product e.g. (cafee or new type of sandwich) based on transactional data from point of sale (POS) system?
also can you provide us the (pbix) file if possible?
sure here is the link to download the PBIX file: https://github.com/f-benoit/PowerBI/raw/main/AB%20Testing/AB%20Testing.pbix
Hi Ben!
Thank you for this guide.
You described it so well and I have used it as inspiration for my own dashboard.
Hi Hana,
Thanks for your comment I’m glad that it helped you!
Seems like, there is a typo here: P-value =
1 – ABS ( NORM.DIST ( [Z Score], 0, 1, TRUE ) )
Should this not be: P-value =
1 – ( NORM.DIST ( ABS([Z Score]), 0, 1, TRUE ) ) ?
NORM.DIST will always return a positive value as its CDF.
Hi Amitabh,
Yes, you’re absolutely right thanks for spotting the typo!
Since I always had a positive z-score I didn’t realize that I put the Abs at the wrong place, thanks again.
Very lucid and exhaustive both in terms of concepts and techniques. I really appreciate your efforts to help fellow humans.
Dear Ben,
This post is very lucid and exhaustive both in terms of concepts, and techniques. I really appreciate your efforts to help fellow humans.
Thank you very much
hello Ms.P
Thanks a lot for your comment and I’m glad to know that you find this post helpful 🙂
Dear Ben,
This post is very helpful. I have a question for the script :
Ctrl Group Conversion % =
CALCULATE (
[conversion%],
ConversionRateABTesting[test_assignment] = “Control Group”
Does that mean to calculate the average of conversion% for Control Group? if it is, I did test in the excel, it seems I got different result for this value.
)
Hi Wenny,
thanks for your comment!
This measure is supposed to calculate the % of Conversion among the total visit assigned to the control group.
For the control group, you should have 3,306 visits and 65 leads thus 65/3036=2.41%.
In the “COnversion%” measure I’m using the average(IsConvert) function to calculate the ratio but since “IsConvert” can have only 0 or 1 it gives the same result (65*1+2971*0)/3036.
Does this answer your question?
Many thanks Ben. Much appreciated. It is really helpful.
Could you please interpret how the confidence interval value impact on the A/B testing result in your example? I did some research, but I could not find better interpretation for it.
Thank you in advance.
Best regards,
Hi,
Thanks for the amazing blog! So helpful, and written so even a power BI beginner like me can follow it through:)
Just a questions regarding the calc.
Assuming I am doing a test , and I would like to analyze the test as a whole, and then per each country or other dimension. Will the calculation be valid if I use filters or other dimensions?
Hi Yael,
Thanks for your comment!
As for your question, a short answer would be “yes” but it depends.
To elaborate a bit more what you are referring to is called if I remember well “post segmentation” you run the test as a whole for a random population then you segment your result by country or other segments (age, sex, browser…)
For the DAX code, it should work without any problems if not let me know so I can fix it :), but In terms of statistics, in theory, it should work but whether this is a valid approach is debatable…
First, you’re not sticking to your initial assumption (“control group” (without any filter) vs “test group” (without any filter) and also slicing the data into too many samples (each country and other dimensions..) will increase the risk of false positives.
So to avoid false positives, if after filtering your data you were to find a significant result for a specific subset I’d rerun an AB test for that specific subset especially if this subset was small.
Hi,
Thank you for you blog!
Could you tell me about CI table, how to calculate z value if I have three groups?
Hi Chris,
Sorry for the late reply, I had been away for a while 🙂
I think you may need to consider using ANOVA for your scenario this is the most common approach for multiple comparison problems.
An alternative approach is to repeat your test A vs B then A vs C then B vs C, but having many variations also increases the risk of having a false positive.
Fantastic article! I’ve been able to re-create this step by step in my own report.
I actually made a switch where you can select what metric you want to use. Probably frowned upon from the scientific community but I think it’s cool to see which metrics were impacted significantly and which weren’t.
A question on the standard error. Your formula works when you have a binomial distribution with % ranging from 0 to 1. How would you adapt it to include a metric such as session time (in minutes) which is a normally distributed variable? I looked up the formula and it seems like you need to divide the St.Dev by the number of samples. Would you calculate the st.dev in a separate table? My underlying data is already aggregated into several categorical dimensions.
Hi Lucas,
Thanks for the comment 🙂
Are you able to share the PBIX file so I can have a clear understanding of the needed adjustment? If I understand well you need to use the formula SE=Std/Sqrt(N) – Std for sample standard deviation and N for the sample size square root
You can do that for both groups ctrl and var group
I cannot access the PBIX file. 🙁
Hi Arka,
Did you try with this link?
https://github.com/f-benoit/PowerBI/raw/main/AB%20Testing/AB%20Testing.pbix
Dear Ben, I am working recently in the field of data analytics and exploring the topics and subjects of which A/B testing is one. It’s really amazing that people like you contribute in the learning environment of others. Despite that I didn’t understand everything in your article, but of course your structure and how you explain is wonderful and you’ve added the .pbix and .csv files so that we can do the test ourselves. Thanks again,
Hi Tarek,
thanks for your comment I’m glad to hear that this post has been helpful for you 🙂
feel free to reach out if you have any questions about this post.
Ben
Hi Ben, this post is really great for people like me who want to learn more about AB Testing on Power BI. I noticed that there might be a typo in the article. The formulas for Maximum Uplift and Minimum Uplift do not exactly match the DAX function. The denominator of the formulas is shown as Var Group, but in the DAX function, it is shown as Control Group. I believe it should be Control Group.