Human Resources Data Analytics
Using predictive analytics to predict the leavers.
The dataset contains the different variables below:
- Employee satisfaction level
- Last evaluation
- Number of projects
- Average monthly hours
- Time spent at the company
- Whether they have had a work accident
- Whether they have had a promotion in the last 5 years
- Department
- Salary
- Whether the employee has left
*This dataset is simulated
By using the summary function we can obtain the descriptive statistic information of our dataset:
Data preparation:

Followed by the str function which returns data types of our variables:
Looking at my data I noticed that some variables are int type but can potentially be a factor type:
Using the Unique function I can clearly identified all the factor variables such as work_accident, left, promotion_last_5years…

To convert a data to a factor type I use the function as.factor():
eg with the variable left: hr$left<-as.factor(hr$left) I just double check that my variable is now a factor type: str(hr$left) –> Factor w/ 2 levels “0”,”1″:
Descriptive statistics:
Once our data are well cleaned and tidied up I can plot some charts to get some information about the data.
I first want to look at the distribution of each variable alone and then I’ll compare two variable with each other so I can figure out whether our data are correlated or not.

The satisfaction_level variable looks like a multimodal distribution as well as last_evaluation and average_monthly_hour.
The first thought that comes to my mind hen I look at the satisfaction_level distribution is that the left peak is very likely to contains the leavers.
Density comparison:
I will no compare the density for different variables:
First thing I want to analyse is satisfaction_level against the variable left.

This chart shows satisfaction level density for the variable left. We can clearly see that employees poorly satisfied are more likely to leave than highly satisfied ones.
Now I wonder if satisfaction_level is related to the salary:

Again we can observe a small peak on the left so we can tell that the salary has an impact on the satisfaction_level however this impact is not very significant which implies that there should be other variables correlated to the satisfaction_level.
Let’s compare couple of other variables against left:


Time_spend_company and average_monthly_hours seem also to have a little impact on the variable left.
SO far I have compared only continuous variables with discrete variables.
I am now interesting to compare the salary variable (low, medium, high) with the variable left (0 or 1).
One way to do that is by using a contingency table which returns the number of leavers/ non leavers for each salary category and then figure out if the variables are distributed uniformly.
The proportion table allows to get the percentage of leavers for each salary category instead of the number which make it easier to analyse.

And indeed the variables “left” and “salary” are clearly uniformly distributed.
The percentage of leavers among “high salary” category is only 6.6% while the proportion for the “low salary” is 29.6%.
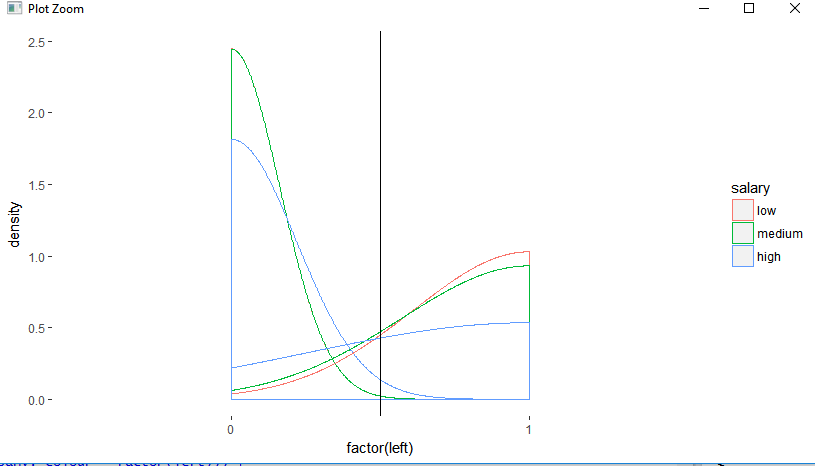
We can also visualise this result by plotting factor left on the x abscisse and get a line for each category salary.
By using a threshold of 0.5 we can also see that density of leavers is much bigger on the right of vertical line and opposite for the high salary which obviously implies that employees with lower salary are more likely to leave than employees with huger salary.
Correlation and conclusion before further analysis:
OK, so far we have built quite a lot of charts and we can already predict an employee with a low salary, low satisfaction_level and who spend a lot of time in the company is very likely to be a leaver.
However our dataset is simulated and contains only few variables, usually, datasets are much bigger and contain a lot of columns so plotting every single variable with with one another to find a correlation will be too long.
One way to get a quick picture of all the correlation among numeric variables is to use the function cor():

Unfortunately, the cor() function does not produce tests of significance, also, this coefficient tells only about the linear relation between these variables and these variables are not linearly correlated
Data splitting: training 70%, testing 30%
In order to test the accuracy of our models we have to create a training subset which we will use to build our models and to create a testing subset which we will use to test the accuracy of our models.
By using the sample split function we can split our dataset into two subset.
By passing the independent variable “left” the split function will also make sure to keep the same proportion of leavers in both subset.
I just used a continence table on our two subsets to make sure we do have the same proportion of leavers, which indeed are still equal.

Let’s build our predictive models
I will implement couple of different models and then compare their accuracy to find out which model model is the most accurate.
The different model that I will build are:
- Logistic regression
- Classification tree (CART) (with different parameters)
- Minimum buckets = 100
- Minimum buckets = 50
- Minimum buckets =25
- Cross Validation for the CART model
- Random Forest
Logistic regression
modelglm<-glm(left~.,data=train,family=”binomial”)
test$prediction.glm<-predict(modelglm,type=”response”,newdata=test)
summary(modelglm)

Here the summary result of the regression logistic model, to be honest this is the first time I have ever seen a model with such significant variables.
Satisfaction_level, number_project, time_spend_company, salary and work_accident are really significant they have a p-value equal to less than 10^-16 but remember that the dataset is simulated so this is not too surprising.
As all the variables are significant I will keep all of them in model but I am sure I could easily removed few variables from this model as I suspect some multicollinearity between certain variables.
The Area Under the Curve of my model is quite good as 0.826 is close to 1.
The ROC curve is a way to evaluate the performance of a classifier using the specificity and sensitivity, the AUC has its pros and cons but still widely used.
#Hopefully I will write a post specially for the AUC and the other ways to compare different classifiers.

Decision Tree (Model CART)
Now I will build three different trees one with a minimum bucket/leaf of 100 then 50 then 25.
- CART min bucket=100:

I like using trees to demonstrate and explain the relationship between the data because it does not require any math skill do be understood.
Obviously the math behind it is harder than a linear regression or a K-means algorithm but the result given given by a decision tree is very easy tor read.
I this tree for example an employee with a degree of satisfaction >= 0.46 and number_project >= 2.5 and average_monthly_hours >=160 will be predicted as a leaver.
- CART min bucket=50:

- CART min bucket=25:

More we decrease the number of minimum bucket in our model more the tree will get bigger. It’s not always easy to set the minimum bucket of our tree as we want to avoid over fitting or under fitting our model.
So far I have built three classification tree models one regression logistic and I’ll test those models later against my test subset.
Cross Validation
K-fold cross validation consist in splitting our dataset into k subset (10 in our example) and the method is repeated K-times.
I will talk more about k-fold CV in another post but in summarise k-fold CV is very useful for detecting and preventing over-fitting the data especially when the dataset is small.
Each time one of the subsets is used all the other subsets are put together to form the training set.
Every single observation will be in the testing set exactly once and k-1 times in the training so the variance will be averaged over the k different partitions so the variance will be much lower than a single hold-out set estimator.
Random Forest